
Every now and then we have to establish a new development environment on our machine. Installing lots of tools can get really cumbersome as we are obliged to remember what we need and in what order the installations should be run. In this post I will show you an example bash script that I use for installing a base set of tools. The script can be easily customized and you can fork it on GitHub and adjust to your needs. I strongly recommend using this in your company to make sure that every programmer will be able to install all tools required to work on a given project in a matter of minutes.
What we are going to build
We will bundle installation of Angular, Docker, Guake, Node.js 12 (with npm) and OpenJDK 11 in a single bash script. As a result we will be able to set up everything with one simple command:
|
1 |
$ sudo ./install.sh guake docker openjdk nodejs angular |
The script will also provide us with verification messages for all tools installed. In case of any failure the script will exit and the error message will be printed in the console.
The finished project is available in the GitHub repository – little-pinecone/ubuntu-web-dev-tools-installer.
Architecture overview
I divided the script into separate files to ease the customization and to adhere to the Open/Closed Principle. The support directory contains variables and helpers. In the tools directory we have one installation and one verification script for every tool (e.g. angular.sh, angular_verify.sh). Testing the script is possible thanks to the custom Docker image enclosed. The install.sh file holds the logic for the overall process and refers to the other files when needed. You can see the project tree on the image below:
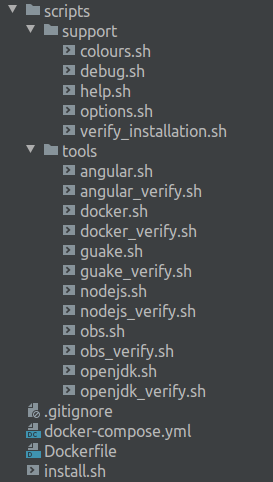
Requirements
- I work on Ubuntu 18.04, you can check your version with the following command:
12$ lsb_release -dDescription: Ubuntu 18.04.3 LTS
Usage
- Copy the
install.shfile alongside with thescriptsdirectory to your machine, or even better, clone the whole repository:
1$ git clone https://github.com/little-pinecone/ubuntu-web-dev-tools-installer.git - Check out the files permissions and, if needed, adjust them so the script can be executed. See the the example below:
123$ chmod 744 install.sh$ ls -la-rwxrwxr-- 1 root user 1123 Jan 15 17:09 install.sh - To see all available options type the following command:
1$ ./install.sh -h - Prior calling the installation scripts, the
apt update -ycommand is performed automatically. Therefore, you are not required to update the system on your own. - The installation commands will be run in the same order in which you passed the parameters. For that reason remember to place the required software before the one that requires it.
- To install tools, type the following command with
sudo, providing files from thescripts/toolsdirectory as parameters. Do not specify the files extension. In the following example we install Angular after Node.js, because Node is required if you want to use Angular:
1$ sudo ./install.sh nodejs angular guake
You will be prompted to accept the command:
![]()
- To run only the verification scripts for provided tools use the
-voption. If you call a non existing script, the error message will be printed. You can see an example command below:
1$ ./install.sh -v nodejs angular guake nonexisting

Testing
Requires docker to be already installed on your machine. Checkout scirpts/tools/docker and run $ sudo ./install.sh docker if the script satisfies your needs. |
The project contains Dockerfile and docker-compose.yml files to provide you with an Ubuntu18.04 instance where you can test the script. All *.sh files are already copied to the /home directory inside the container.
Start the container based on the provided image:
|
1 |
$ docker-compose up -d |
Enter the container:
|
1 |
$ docker exec -it ubuntuwebdevtoolsinstaller_test_1 /bin/bash |
List the /home directory content to see that you can access the install.sh file and the scripts directory:
|
1 2 3 4 5 6 |
/home # ls -la total 16 drwxr-xr-x 1 root root 4096 Jan 15 14:45 . drwxr-xr-x 1 root root 4096 Jan 15 14:46 .. -rwxrwxr-- 1 root root 1129 Jan 15 13:21 install.sh drwxr-xr-x 4 root root 4096 Jan 15 14:45 scripts |
You can test the ./install.sh command without risking unwanted changes on your machine. Do not use sudo inside the container, run the script like in the example below:
|
1 |
$ ./install.sh nodejs angular guake |
If you’ve changed the image, or any script that you intend to test there, remember to remove the container and rebuild the image with the following commands:
|
1 2 |
$ docker container rm -f ubuntuwebdevtoolsinstaller_test_1 $ docker-compose build |
Then you can create a new container and enter it:
|
1 2 |
$ docker-compose up -d $ docker exec -it ubuntuwebdevtoolsinstaller_test_1 /bin/bash |
Customization
You can fork the project and add your own installation and verification scripts — it is easy to keep a whole “library” of these scripts in your GitHub repository. Every time you call the $ sudo ./install.sh command you may pass any file that is suitable for you at the moment as a parameter.
Remember:
- keep commands regarding one tool in a separate
*.shfile — it will be easier to debug failures and retry installation; - a file name should clearly indicate what tool is being installed;
- a verification script file name should contain
_verifysuffix added to the same name as used in the installation file; - put your installation and verification scripts in the
scripts/tools/directory; - put the auxiliary scripts in the
supportdirectory.
Bash script explained
How to divide one shell script into multiple files
We could keep all the code in a single *.sh file. However, I wanted to ease adding new scripts according to the future needs. Therefore, the main install.sh file uses the source command to execute scripts from separate files in the same shell:
|
1 2 3 4 |
#!/bin/bash … source ./scripts/support/verify_installation.sh … |
From the source manual:
|
1 2 3 4 5 |
$ source --help Execute commands from a file in the current shell. … Exit Status: Returns the status of the last command executed in FILENAME; fails if FILENAME cannot be read. |
The scripts still share settings and variables, but it is easier to customize and maintain the code.
How to exit shell script if any command fails
When we are combining many commands to be automatically run one after another, we have to be able to terminate the script and debug in case any of them fails . In the install.sh file we put the following settings for the shell:
|
1 2 3 4 |
#!/bin/bash set -e source ./scripts/support/debug.sh … |
From the set command manual we know that the option -e terminates the execution in case of any error:
|
1 2 3 4 5 |
$ set --help Set or unset values of shell options and positional parameters. Options: … -e Exit immediately if a command exits with a non-zero status. |
Then we include the debug.sh file containing the code responsible for tracking the last executed command and printing its exit code:
|
1 2 |
trap 'last_command=$BASH_COMMAND' DEBUG trap 'echo $debug"\"${last_command}\" - the last command exited with code $?. $reset_colour"' EXIT |
In order to see which command failed and what was the cause, we save information about the command that is currently being run as the last_command during the DEBUG SIGNAL_SPEC, and on EXIT signal we print that command and its exit code to the console. From the trap command manual:
|
1 2 3 4 5 |
$ trap --help Defines and activates handlers to be run when the shell receives signals or other conditions. … If a SIGNAL_SPEC is EXIT (0) ARG is executed on exit from the shell. If a SIGNAL_SPEC is DEBUG, ARG is executed before every simple command. |
E.g. if we run our script with the following command:
|
1 |
$ ./install.sh -guake -docker -openjdk -nodejs -angular |
and we got information about failure of a command executed from the openjdk.sh file, we know that all previous commands were run without errors and, after fixing the bug, we can resume the installation by typing:
|
1 |
$ ./install.sh -openjdk -nodejs -angular |
into the terminal.
When no errors occurred, we will see the last command printed with the 0 exit code; for my install.sh script the last line of the console output will be:
|
1 |
"echo "$debug END OF THE install_tools.sh SCRIPT. $reset_colour"" - the last command exited with code 0. |
How to write a function
To make the code readable you can always extract some logic into a separate block of code. Remember to define the function before it is used, like in the example from the install.sh file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
… function install_tool() { if [ -e ./scripts/tools/"$file".sh ]; then source ./scripts/tools/"$file".sh else echo "$error Installation script not found for: $file. $reset_colour" echo "" fi } … for file in $tools; do install_tool done … |
Options and parameters
How to pass options — adding help option to your script
To enable users to call your scripts with options, we need to read them in a while loop using getops, like in the example from the install.sh file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
while getopts thv option; do case "${option}" in t) test=true ;; h) source ./scripts/support/help.sh exit 0 ;; v) verify_only=true ;; *) echo "$error Unknown option used. Type './install.sh -h' to see the available options. $reset_colour " exit 1 ;; esac done |
getopts is used by shell scripts to parse positional parameters. In my case, the
thv string contains the characters that will be recognized as valid and put one after another in subsequent iterations into the option variable.
Calling the command with the -h option will result in executing commands enclosed in the help.sh file (printing the manual) and exiting with code 0:

How to pass parameters
Bash keeps the position of the latest argument in the OPTIND variable.
From the bash documentation:
Each time it is invoked,
getoptsplaces the next option in the shell variable name, initializing name if it does not exist, and the index of the next argument to be processed into the variableOPTIND.OPTINDis initialized to 1 each time the shell or a shell script is invoked.
After we had traversed through the available options (thv) we want to set position to the beginning of the rest of the arguments passed to the command (file names). We have to do it manually as stated in the docs:
The shell does not reset
OPTINDautomatically; it must be manually reset between multiple calls togetoptswithin the same shell invocation if a new set of parameters is to be used.
We are going to apply the shift [n] command that shifts the positional parameters to the left by n. We want to start reading parameters from the position next to the one that was reached by the while loop — the first file name passed to the script. To remove all the options that have been already parsed by getopts we use the following line:
|
1 |
shift "$((OPTIND-1))" |
Just for illustration, calling the $ ./install.sh -v openjdk command without shifting this position would result in something like this:

The -v option was read again, the second time as a parameter for a file containing a verification script.
I use the array with file names in several places, therefore I assigned it to a custom variable, and then printed them for the confirmation message:
|
1 2 |
tools=$@ echo "$info The following tools will be installed: $tools. Would you like to continue?: y/n (y) $reset_colour" |
How to read input from a user — adding confirmation to your script
In the docker_verify.sh file you can find two simple if statements. First one checks whether the test option was omitted while calling the script; second one checks whether our user confirmed running a test docker container:
|
1 2 3 4 5 6 7 8 9 10 |
… if [ "$test" != true ]; then echo " Would you like to run test docker container?: y/n (n)" read -r decision if [ "$decision" = y ]; then echo "$(docker run hello-world)" fi elif [ "$test" = true ]; then echo "$(docker run hello-world)" fi |
As you can see, the script will run a test docker container automatically if the -t option was passed when calling the command. In other case, we can ask a user directly for their confirmation before running any testing command.
How to read files in a loop
In the install.sh script we have the following function sourcing the files that we are required to have in the /scripts/tools directory:
|
1 2 3 4 5 6 7 8 |
function install_tool() { if [ -e ./scripts/tools/"$file".sh ]; then source ./scripts/tools/"$file".sh else echo "$error Installation script not found for: $file. $reset_colour" echo "" fi } |
Furthermore, we assigned parameters left after reading options to the tools variable:
|
1 |
tools=$@ |
Finally, we can easily call the function in a for loop that iterates over the elements in the tools variable:
|
1 2 3 |
for file in $tools; do install_tool done |
How to check whether a file exists
Use the -e expression to determine whether the file exists:
|
1 2 3 4 5 6 |
if [ -e ./scripts/tools/"$file".sh ]; then source ./scripts/tools/"$file".sh else echo "$error Installation script not found for: $file. $reset_colour" echo "" fi |
How to check whether a string is empty
Use the -z expression to verify whether a string is empty, like in the example below:
|
1 2 3 4 5 6 7 8 |
echo "$info The following tools will be installed: $tools. Would you like to continue?: y/n (y) $reset_colour" read -r confirmation if [ "$confirmation" = y ] || [ -z "$confirmation" ]; then apt update -y for file in $tools; do install_tool done fi |
According to the code above, a user can confirm the default decision “y” simply by pressing Enter. The confirmation variable will be null in that case, which results in proceeding with installation process.
How to colour the script’s output
I use the tput command with the setaf option to determine colours of the messages you can see in the console. In the support/colours.sh file you will find all variables I use to set or reset output colours:
|
1 2 3 4 5 |
reset_colour=$(tput sgr0) error=$(tput setaf 1) info=$(tput setaf 4) success=$(tput setaf 2) debug=$(tput setaf 3) |
- 1 — red,
- 4 — blue,
- 2 — green,
- 3 — yellow.
To print a blue message, I start it with the $info variable. At the end of the message i put the $reset_colour variable to leave the rest of the output in the default colour:
|
1 |
echo "$info Tools installation summary$reset_colour" |
You can change the colours as you wish, however I recommend to name variables according to their meaning and not necessarily the specific colour they are holding at the moment. After all, if you decide to print the debug messages in gray, you won’t have to fix every single occurrence of that variable in the code.
Useful resources
- Bash Reference Manual
- Basics, Conditional expressions, Concatenation, How to find the length of an array, Increment and decrement variables, Checking variables for null values, Method in a shell script, Bash local and global variables
- Use getops in bash, Why shift options, How to distinguish between options and parameters, Passing arguments
- Read user input on the same line as the prompt
- Bash tutorial, Another bash tutorial
- Reusable scripts
- Exit on error
- Colouring bash output
Photo by Anggoro Sakti on StockSnap