
Having a sufficient sample of lifelike data greatly improves the application development process. In most cases, when we start working on a project, we don’t have the luxury of having a well-stocked database we could use in development and testing. However, we can easily create such a database using a random data generator.
I’m going to enclose some code examples to better illustrate the points made in this article. For this purpose, I’m going to use a flexible and user friendly random data generator for Java – Dummy4j (of which I am a contributor). In order to use the generator in a project we need to include the dummy4j maven dependency in our pom.xml file (check the maven repository for the latest version):
1 2 3 4 5 6 7 | <!--pom.xml--> … <dependency> <groupId>dev.codesoapbox</groupId> <artifactId>dummy4j</artifactId> <version>0.6.0</version> </dependency> |
Now we can create an instance of the generator and see the many ways in which it facilitates our work:
1 | Dummy4j dummy4j = new Dummy4j(); |
1. Helps with lack of real life data
In case of many prototypes or MVPs there is no actual data that can be used on a development environment. The data simply doesn’t exist yet. Manual input is a waste of resources, getting even more costly as time goes on and work on an app progresses. Therefore, using a random data generator to fake appropriate information saves a lot of precious time.
Generating 1000 random birthdays for people aged 18 to 65 can be achieved with DateAndTimeDummy as follows:
1 | List<LocalDate> dates = dummy4j.listOf(1000, () -> dummy4j.dateAndTime().birthday(18, 65)); |
Example result: 1984-03-30, 1965-04-08, 1981-03-14, 1968-11-03, 1998-10-05, 1984-12-21, 1969-07-04, 1991-08-24, …
2. Protects sensitive data
Any improper handling of personal data can have serious consequences for our company if it violates legal restrictions such as the General Data Protection Regulation. When the production environment processes sensitive information, such as personal data or copyrighted material, we need to work with fictitious data sets during development.
You can fake some confidential data using FinanceDummy like in the example below:
1 | String creditCard = dummy4j.finance().creditCard().toString(); |
Example result: CreditCard{number='4150 2591 8277 4861', provider=Visa, ownerName='Zoe Anderson', ownerAddress='10 Amos Alley, 1234-55 North Austinshire, Canada', "expiryDate='05/2030', securityCode='111'}.
3. Provides large sets of data for optimization tests
Once our code meets business specifications it should be verified against performance requirements. Testing whether the optimization constraints are met demands a large and varied data set. Using production data for this purpose is not only risky and ineffective, but sometimes also impossible, as the dataset might still be too small for some performance tests. Furthermore, the real data may not cover edge cases and then has to be manually changed by team members. This can quickly lead to time-wasting and dangerous inconsistencies in the test results.
If a system processes a large amount of long urls, we can provide the desired amount for the tests with the following code:
1 2 3 4 5 | List<URL> urls = dummy4j.listOf(1000000, () -> dummy4j.internet().urlBuilder() .withQueryParams(3) .withFilePath() .minLength(200) .build()); |
Example result: https://www.consectetur.org/dwivaizwov.html?eos=183769102&eligendi=magni&eius=liberooepnuimzlevflbtunhowabdcpslmwgkskzhobqtzpvscmfdxvkswahceeyvtvpdjzxokuroxdwlhgqelzltbugvstgltkulioqjvhtrmzmncpkcmaiqb, …
4. Allows for repeatability
Inconsistencies in test results can be eliminated when all team members use the same data set. Debugging tests that work on an input generated with the same seed is much more straightforward, as the tests are run against a consistent data set. We can also share our seed with other team members when we want to replicate an issue we found and solve it together.
If you want to work with the same set of data, set the seed while creating the dummy with the Dummy4jBuilder:
1 2 3 | Dummy4j dummy4j = new Dummy4jBuilder() .seed(12345L) .build(); |
5. Reduces boilerplate code
It’s important to keep the codebase free from clutter. Hard coded values lead to bloated code and obscured business logic. They tend to be constantly modified by all team members according to their current needs which leads to inconvenient merge conflicts. When a team has to manually maintain even a humble set of values it’s easy to duplicate one or misspell another which leads to code that is not only messy but also inaccurate. Fake data sets are not part of the application, hence they should not litter the code.
Compare those two ways of faking 50 tertiary education institutions:
1 2 3 4 5 6 7 8 9 10 | public List<String> getTertiaryEducationInstitutions() { return Arrays.asList("Boston College", "Houston University", "Seattle College", "Detroit University", "Chicago College", "Boston College", "Houston University", "Seattle College", "Detroit University", "Chicago College", "Boston College", "Houston University", "Seattle College", "Detroit University", "Chicago College", "Boston College", "Houston University", "Seattle College", "Detroit University", "Chicago College", "Boston College", "Houston University", "Seattle College", "Detroit University", "Chicago College", "Boston College", "Houston University", "Seattle College", "Detroit University", "Chicago College", "Boston College", "Houston University", "Seattle College", "Detroit University", "Chicago College", "Boston College", "Houston University", "Seattle College", "Detroit University", "Chicago College", "Boston College", "Houston University", "Seattle College", "Detroit University", "Chicago College", "Boston College", "Houston University", "Seattle College", "Detroit University", "Chicago College"); } |
1 2 3 | public List<String> getTertiaryEducationInstitutions() { return dummy4j.listOf(50, () -> dummy4j.education().tertiaryInstitution()); } |
In the first code snippet I didn’t even try to fake unique or lifelike values and it still took me much more time than the second snippet. The code readability is also greatly affected.
6. Facilitates keeping fake data in touch with project requirements
In an example financial application we may get a requirement to support Visa credit card numbers and decide to hardcode 100 values with the correct check digits (compliant with the Luhn formula) and a proper provider IIN. If we are suddenly asked to add support for Maestro and American Express when we don’t have resources to manually add similarly representative data sets, we can either:
- postpone the data update for a more convenient time, which does not solve the problem, but still needs to get through our Product Owner and increases communication costs;
- hastily add just a few examples for new providers, possibly overlooking some formatting rules or required IIN ranges, which provides only fragmented support for the new companies.
In the first case, essential business requirements may be delayed, making the cooperation with stakeholders problematic. In the latter, we may inadvertently mislead decision-makers that the requirement is fully met when in fact it is not, and the application will crash upon encountering real credit card numbers.
Alternatively, we can generate the data for every new provider like this:
1 2 3 4 | dummy4j.listOf(100, () -> dummy4j.finance() .creditCardNumberBuilder() .withProvider(CreditCardProvider.MAESTRO) .build()); |
Another added benefit is that it’s just as easy to delete data when the scope of a project is cut. Thanks to this, we won’t risk that some outdated data will remain.
In the end, we want to ensure that our Product Owner has the most accurate understanding of the current capabilities and performance of the product.
7. Supports extendability
No matter how many data sets can be fabricated by a generator, there are cases when you have to provide custom definitions to accommodate your particular requirements.
7.1 You can provide data in multiple languages
You don’t need to worry if your code demands values in multiple languages. Extending data sets to support other languages is effortless. Firstly, provide the locale list when creating a Dummy4j instance:
1 2 3 4 5 6 | Dummy4j dummyForFinnish = new Dummy4jBuilder() .locale("fi", "en") .build(); Dummy4j dummyForFrench = new Dummy4jBuilder() .locale("fr", "en") .build() |
Secondly, add the new locale files with the definitions under your resources/dummy4j path:
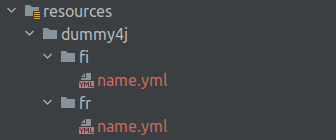
As a result, the generator will provide definitions from all available locales (en, fr and fi). The How to generate fake data in multiple languages with Dummy4j post explores this possibility in more depth.
7.2 You can provide custom definitions
If you want to add custom definitions to the pool, just enclose them in a file located in the resources/dummy4j/ directory according to the following pattern:
1 2 3 | en: my_definitions: thing1: [ "abc", "def", "ghijk" ] |
Now you can reach them using the built-in expression resolver in the following way:
1 | dummy4j.expressionResolver().resolve("#{my_definitions.thing1}") |
When the custom definitions reside in a different directory, you can still use them. Add the path to the list of supported paths when instantiating the generator:
1 2 3 | Dummy4j dummy4j = new Dummy4jBuilder() .paths("my/custom/path", "dummy4j") .build(); |
8. Provides adaptable data sets
Requirements towards data may change often. Using a flexible fake data generator allows programmers to keep control over received values.
8.1 Supports data variety
Dummy4j allows for generating data according to different requirements, e.g. a URL can be created in many different configurations:
1 2 3 4 5 6 7 8 9 10 | URL urlWithParams = dummy4j.internet().urlBuilder() .withQueryParams(2) .build(); URL urlWithFile = dummy4j.internet().urlBuilder() .withFilePath() .build(); URL urlWithMinLength = dummy4j.internet().urlBuilder() .withCountryTopLevelDomain() .minLength(100) .build(); |
8.2 Provides unique values
The code shown below makes sure that our list of names does not contain duplicates:
1 | dummy4j.listOf(100, () -> dummy4j.unique().value("unique-names", () -> dummy4j.name().fullName())); |
8.3 Makes it easy to change the amount of generated values
In the following snippet we can see how easy it is to alternate the amount of generated data:
1 2 | List<String> passwords = dummy4j.listOf(10, () -> dummy4j.internet().password()); List<String> passwords = dummy4j.listOf(100000, () -> dummy4j.internet().password()); |
We can even go a step further and randomize the amount itself:
1 2 | List<String> passwords = dummy4j.listOf(dummy4j.number().nextInt(10, 100000), () -> dummy4j.internet().password()); |
8.4 Supports nullable values
We can generate a data set where some values are nullable, e.g half of the medical disciplines generated with the following line will be null:
1 | dummy4j.listOf(10, () -> dummy4j.chance(1, 2, () -> dummy4j.medical().discipline())); |
9. Supports catching more edge cases
It’s hard to foresee all potential bugs when the same person has to translate business requirements into code, write tests and come up with fake data. When a random data generator provides sufficient data variety, the programmer can focus on creating a reliable test suite and finding more edge cases. E.g. if an application has to deal with addresses, a developer can easily generate a list of fake locations with the following line:
1 | dummy4j.listOf(100, () -> dummy4j.address().full()); |
This allows team members to pay more attention to the actual business logic and make sure the code works well with various values.
10. Enables more impactful product presentations
From time to time we need to demonstrate the capabilities and functions of a product and the overall progress of the work. When using a real data set is out of the question, we need to generate a fake one. However, a presentation based on a few hand-coded values may not mesmerize clients.
Any system will look more advantageous when the data used in the presentation mimics business logic. E.g. if an application has to process scientific publications related to natural sciences we can generate a set of fake titles with the following line:
1 | dummy4j.listOf(50, () -> dummy4j.researchPaper().titleNatural()); |
As a result we’ll get titles like: Luminescence Enhancement in Optical Lattices and the One-Dimensional Interacting Bose Gas, Alveolar Mimics with Periodic Strain and its Effect on the Cell Layer Formation, Molecular Cloning and Subcellular Localization of Six HDACs in the Radiation Induced Perivascular Resistant Niche (PVRN) and the Induction of Radioresistance for Non-Small Cell Lung Cancer (NSCLC) Cells, Transcriptome Analysis of Phosphorus Stress Responsiveness in Plant Secondary Metabolites Production, …
11. Provides large data sets useful for designing pagination and sorting
Implementing and testing pagination and sorting is more reliable when we have a considerable quantity of database records to work with. Providing a thousand objects more is trivial when they are generated automatically. Thanks to this, we can easily verify how our code deals with paging and sorting a huge number of entities.
12. Enables more scrupulous UI testing
If an app serves data visually, we can better test its UI on a large set of varied data. Not only does the abundance of available values help verify that the layout of tables, cards, lists, and many other UI elements is flawless, it can also reveal some formatting issues (e.g., incorrectly formatted credit card numbers that vary in length or formatting patterns).
More on using a random data generator for Java
- Explore the convenience methods available in Dummy4j to see how easy it is to generate random data.
- Visit the current list of out-of-the-box dummies to see if you can find what you need. If not, you can easily customise Dummy4j to support any data set you want.
- How to generate fake data in multiple languages with Dummy4j post.
- How I enhanced my project by generating custom fake data with Dummy4j article.
- Visit the project repository on GitHub:

Photo by Jeremy Bishop from Pexels